Scotland decides. What about Twitter?
At 8pm tonight head of the Better Together Campaign Alistair Darling faces SNP leader Alex Salmond in a televised debate about Scotland’s future. It’s the first, and only, debate between the two big hitters before Scotland decides the fate of the Union on 18 September: “Should Scotland be an independent country?”
But the debate won’t just be taking place at The Royal Conservatoire of Scotland in Glasgow. It will also unfold in the sitting rooms of the millions of people who will sit down and watch. And many of them will take the debate online. Social media has become an extremely important arena for the referendum debate, with both sides investing considerable money and effort into online campaigning – mirroring the general trend of politics going digital. Nowhere more so than Twitter. This is the battleground of a new, digital political commons, where every major event is accompanied by thousands of people trading facts, insults, ideas and thoughts with each other. Tonight we anticipate hundreds of thousands of tweets to be posted as people watch the protagonists doing battle on the screen.
We set up the Centre for the Analysis of Social Media at Demos as the first think-tank unit dedicated to researching digital society. This evening, we’ll be teaming up with the respected pollsters Ipsos MORI to use our technology to tell you what happening in this new digital battleground. As the Twittersphere gets busy, so we will – collecting and analysing the tweets about the debate as they come in, and presenting the results here. In particular, we’ll be looking out for:
· How many people are taking part in the Twitter discussion, in Scotland and in England
· The role of personality and politics in the debate
· What things seem to be capturing public imagination: is it economics or culture? Perhaps something else?
· The boos and cheers of the digital arena towards each candidate
One thing we won’t do is say who ‘won’. As we’ve argued elsewhere, Twitter is not a representative sample of Scotland or England. Indeed, analysis from the online research group Brandwatch has found that online discussion about the referendum tends to be dominated by the ‘Yes’ supporters (and especially men). However, Twitter does offer a handy snapshot of this important new arena of public debate. We’ll never quite know what insight we’ll produce until people start tweeting, so keep watching this space. I’ll be updating every time we have something interesting to share.
— 20.24 update —-
Despite some unfortunate difficulties with STV streaming, we’ve now recieved around 15,000 tweets using the hashtag ‘Scotdecides’. (Of course there would have been many more not using the hashtag, which we haven’t collected).
Of those that we can accurately locate to a city or place, we have collected 4,070 tweets from Scotland and 2,059 from England (many of which were complaining about STV). And a paltry 21 from Wales.
— 20.52 update —
Team is working frenetically – some fascinating data to follow.
In the meantime, we now have around 43k tweets (of which 63 per cent from Scotland). Wales and Northern Ireland pretty disinterested it seems.
— 21.11 update —
As expected, it’s Scottish men that are overwhelmingly part of the Twitter debate. In England, Salmond is barely mentioned at all – it’s all Darling.

— update 21:18 —
Coming in thick and fast now. Men talked more about both; and for both men and women, Darling was mentioned the most.
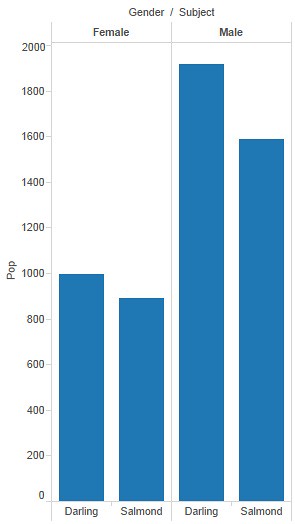
— update 21.25 —
We’ve analysed the hashtags that are being used in conjunction with #Scotdecides. As it stands, it looks like ‘Yes’ and ‘No’ are pretty evenly split.

— update 21.42 —
As the debate draws to a close, we have the ‘boos’ (in red) and ‘cheers’ (in green) for both candidates. As you can see, there seemed to be more booing and cheering for both. (For the first hour).
Salmond

Darling

— Update 21.54 —
A quick additional bit of insight. Positive mentions of both candidates side by side – relatively few for each. (Disclaimer – this is not the same as a ‘winner’: something I would be pretty wary of).

— Final update: 22.08 —
And the last word from here – phew – is the total count.
We collected 104k tweets which used the hastag #scotdecides or the names Salmond / Darling over the course of the debate. Of those for which we could identify a location (approximately 40 per cent) 61 per cent were from Scotland; 38 per cent were in England – with Wales and Ireland pretty uninterested.
Final Final update: 22.28 —
Geo-location of tweets posted during the debate. (Of those available – which is a small % of the total).

— Final word 22.38 —
Thanks everyone for following this.
I’ll finish with an important disclaimer. Twitter users are not a representative set of voters or citizens; and those who posted using the #Scotdecides (our data set) are probably not a representative set of Twitter users. Therefore, I advise caution about drawing very firm general conclusion from these results. The accuracy of the algorithms we built to classify the data sets, although fairly accurate, is never perfect. (Such is the nature of natural language processing). Beware of anyone telling you otherwise!
Jamie
— Post script on methodology —
A number of people have asked a little more information about method, so here’s a quick bit of methodology for the technically minded.
We collected the data from Twitter’s stream Application Programming Interface, using a garden hose access. This provides up to 1% of all tweets posted at any time – and given the relatively low volume of tweets posted here, the limit was not a problem.
Tweets were collected using a simple key word match. We collected all tweets posted anywhere in English which included the hashtag #Scotdecides. This was the hashtag proposed by STV. This sort of hashtag sampling is not a rigorous method to collect data by any means – a lot of tweets would have been missed. But this was a rapid analysis, conducted as the debate unfolded, and so this was a simple way to access large volumes of tweets without much noise.
The tweets were then transferred to bespoke software that we have built in partnership with the University of Sussex, called ‘Method 51’. There will be some more technical reports on that later.
To get the data on locations of tweets, we collated all geo-located tweets (around 1 – 2 per cent); and combined them with all tweets which included the name of a city or town based in the UK (around 30 – 40 per cent) cross referenced against the time zone the tweet was posted.
To determine gender, we used a pre-existing dictionary of names, cross references against the names of those who posted the data. This tends to work with over 90 per cent accuracy.
The technique we used to analyse the sentiment was an automated approach involving ‘natural language processing’ (or NLP). This allows researchers to build models that detect patterns in language use that can be used to undertake meaning-based analysis of large data sets. These were built and applied in different contexts to see where they worked, and where they did not. These models are called ‘classifiers’.
Three analysts train an algorithm to automatically recognise patterns in the text through annotating examples (this is based on rule based patterns – not simply word matches). The classifiers then begin to recognise certain patterns and can then automatically spot the same patterns in much larger data sets. NLP is widely used in the analysis of language in ‘big data’ sets, which are too big for humans to manually analyse, for example, to perform sentiment analysis. We repeatedly tested our model for accuracy against another set of annotated data that was marked up by analysts but not part of the classifier model, and all results presented were only included where the classifiers were working with an overall accuracy over at least 70 per cent (considered fairly good in NLP).
Finding the most commonly shared words used in our data set was simply just a volume analysis on co-occurring words within the data set.