The method in the madness
The idea began light-heartedly – it was an opportunity to road-test the real-time rapid response capabilities of our social media analysis software and methodologies, by applying them to the live debate on Europe between Nick Clegg and Nigel Farage. The arrival of a Newsnight team kicked the operation up a gear, really putting the pressure on to deliver results.
We set out to investigate two things: firstly, the extent to which we could produce meaningful real-time outputs, and secondly, how quickly we could put together more considered analysis of the type we have previously produced on less time-sensitive projects. This post will focus on how we tackled the first of those two challenges, namely the processes behind producing our boo/cheer worm:
‘Method51’, our cryptically named social media analysis platform, was at the heart of our attempt to unpick the Twittersphere as it formed around the BBC Europe Debate on Tuesday night.
Method51 allows analysts to collect data from Twitter and construct Natural Language Processing classifiers that can automatically sort documents into one of a number of pre-defined categories. We published a paper last year detailing some of how that works and a forthcoming paper describes a series of case studies and developments since then.
REAL-TIME BOO/CHEER ANALYSIS
A natural method for visualising real time sentiment has been dubbed the ‘opinion worm’. The first CASM collaboration between the University of Sussex and Demos produced one of these for the X-Factor competition back in 2011. An opinion worm is essentially a constantly updating plot that records the chronology of the ratio between the number of positive and negative points made towards each candidate.
The result is a growing line for each candidate that tracks up when people are being more positive than negative, and down when people are being more negative than positive. In order to drive the positive and negative points we need to automatically analyse the language of people’s comments about the debate. To do that we built two classifiers: one for Clegg, and one for Farage.
Automatically dealing with language is currently one of the most challenging tasks one can ask of computers. It’s also one that’s becoming increasingly popular and important. Two related factors form a significant chunk of the underlying challenge.
The first big problem is that language is contextual. The words and language that people deploy to express sentiment (positivity and negativity) can vary from one domain to the next.
Positive words in one domain can be unrelated to positive words in another. Bigger might be better for one topic, whereas colour is the primary consideration in another. Essentially, we often don’t learn anything by using ‘sentiment bearing’ words from one domain and applying them to another.
But even worse than not learning anything is actively getting things wrong: the sentiment polarity of words can be reversed when taken out of context. An illustrative example came about in our forthcoming study on sentiment towards the Eurozone crisis. David Cameron gave a speech expressing a sceptical view towards the UK’s membership in the EU. Reactions to that speech that employed ‘positive’ language were in fact contributing negative sentiment towards EU membership. In short, context is everything.
The second of our two problems is that people are unpredictable. We knew the debate would be about Europe; however, the specific language people use to express their opinion on particular gaffes and hits of the candidates is very much unknown, and likely to be derivative of the phraseology used at the time.
Our methodology attempted to address both of these concerns. Fortunately, this was ‘round two’ of these debates; the first round was hosted by LBC radio the week before. Our first trick was to pre-emptively collect the reactions to round one by tracking the keywords ‘clegg’, ‘farage’ and ‘lbcdebate’ (the official hashtag) on the evening of Wednesday the 26th.
This gave us training data which allowed us to prepare Clegg and Farage sentiment classifiers before the second debate. Crucially, this data consisted of debate reaction-oriented language about both participants. This is about as close as one could hope to get to the intended target language without using a time machine.
The second trick we pulled was to split the data in two (see fig 1 below); the Clegg dataset contained Tweets that mentioned Clegg but not Farage, and the Farage dataset Tweets that mentioned Farage but not Clegg.
The effect of this was twofold. Firstly, it acted as a proxy getting the orientation of sentiment keywords right, so we wouldn’t confuse positive sentiment about Farage for positive sentiment about Clegg, and vice versa. Secondly, it filtered out the vast majority of conversation that addressed the actual topics and issues raised in the debate – immigration, jobs, trade etc.
FIGURE 1. THE CLEGG AND FARAGE PREPROCESSING FILTERS
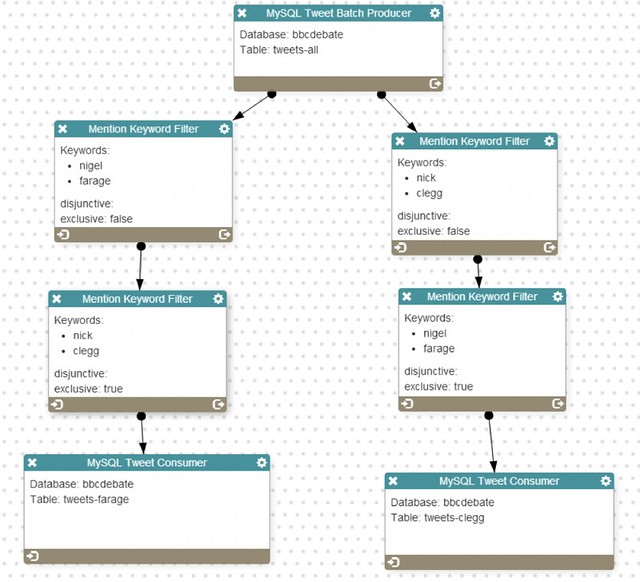
This helped reduce the proportion of messages that addressed issues in the first debate and may consequently not have been about the second debate. Replicating these pre-processing steps on the live data for the second debate helped to curate a comparable dataset for our classifiers to work with.
The upshot of these steps is that we didn’t even try to categorise unpredictable language because it was filtered out, and we made the context problem as small as possible by deterministically distinguishing between the two candidates. Essentially we tried to make the difficult task of dealing with language as easy as possible for our computerised pals. Fig 2 shows the training interface for the Farage classifier.
FIGURE 2. TRAINING THE FARAGE BOO / CHEER CLASSIFIER
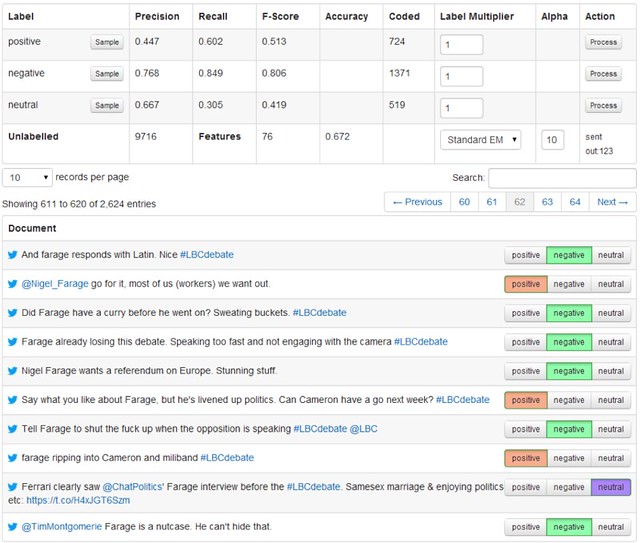
The outputs of our boo/cheer classifiers were exactly as the name suggests – no more nuanced than boos and cheers. They’re not even guaranteed to be in reaction to any particular topic or statement, but should give a sense to the overall mood being expressed towards the candidates. Nuanced reaction analysis can only be achieved through careful examination of the data, and in my opinion, should not even be attempted by automatic real time techniques.
My reading of how our worm behaved is that it did well in two areas; it captured similar characteristics to the applause of the live audience; many of Farage’s points received claps, whereas very few of Clegg’s contributions provoked a distinctly positive response. Farage’s worm shows periodic spikes of positivity, whereas Clegg’s is less dynamic.
It also portrayed a race to the bottom, so that the question to ask of the debates should not be ‘who won’ but ‘who did least badly’. And the answer to that, it seems, was Nigel Farage.
What I found mildly disappointing is that the peaks and troughs displayed by the worm didn’t feel like they particularly matched up to events and statements in the debate. To determine whether this was an accurate reflection of the data, or whether it was something else, is the next task on my agenda for refining Method51’s real-time capabilities.